인덱스란
인덱스란 임의의 규칙대로 부여된 임의의 대상을 가리키는 무언가 를 의미.
데이터 베이스에서의 인덱스는 대용량 데이터 에서 원하는 데이터를 빠르게 찾기위해 사용된다.
- 데이터 조회의 성능을 향상 시키기 위해 사용
- 조회만 향상시키기 위해 insert, update,delete 의 성능을 희생
- 대용량일시 효과가 더욱 좋다.
index 또한 하나의 데이터베이스 객체이며
DB 에 따라 다르지만 스키마 객체 이거나 테이블 내의 객체로 존재하게된다.
index 는 항상 최선의 정렬을 유지하며
index 를 사용하기위한 저장 공간이 필요로 한다.
→ 데이터베이스 크기의 약 10% 정도 차지
인덱스 = 정렬
인덱스가 적용되어있다 라고하는건 결국 데이터베이스안의 데이터들이 정해진 방식으로 정렬이 되어있다는 말이다.
만약 데이터베이스에 저장된 데이터가 인덱스로 잡혀지않을때
어떠한 데이터를 찾고 싶다면 데이터베이스에서 하나하나 찾아야 한다
이렇게 모든 정보속에서 찾는것을 풀스캔 혹은 테이블 스캔 이라 한다.
예로 회원의 nickname 으로 인덱스를 잡은 테이블 일때
select * from member where nickname = 'nick';
위와같이 조건으로 검색을 하게되면 데이터베이스에는 nickname 로 정렬되어있기에 빠르게 찾을수있다.
이말은
select * from member where email = "test";
이렇게 조회하면 인덱스의 효과를 받지 못한다는 말이된다.
1만3829 의 row 를 가진 테이블에서
index 가 잡힌 컬럼과 안잡힌 컬럼을 조회했을때 결과는 아래와같다.
SELECT * from tb_member WHERE id = 500; //1~2ms
SELECT * from tb_member WHERE nick_name = '단정한_어묵_46'; //1~3ms
SELECT * from tb_member WHERE email = '9557m462eh@random.com'; //12~16ms와 저도 인덱스 써보고 싶어요!
모두 자신도 모르게 인덱스를 사용하고있다.
왜냐하면
PK 가있다면 자동으로 인덱스를 생성하기때문이다.
PK 뿐만 아니라 Unique제약 조건을 사용하면 자동으로 인덱스가 생성되는데
위에서 본 인덱스 속도가 사실 해당 제약조건을 컬럼에 추가하고 쿼리를 실행한 결과이다.
SELECT * from tb_member WHERE id = 500; // PK
SELECT * from tb_member WHERE nick_name = '단정한_어묵_46'; // unique
SELECT * from tb_member WHERE email = '9557m462eh@random.com'; //none
진짜 인덱스를 쓰고 있는건가
컴퓨터의 CPU 가 있다면 DB에는 옵티마이저 라는 존재가있다.
개발자가 SQL 을 작성하면 이게 즉시 실행되는것이 아닌
옵티마이저가 쿼리문에 대해 실행계획을 세우고 이 실행계획의 예상 비용을 산정한후에
최고의 효율을 가지고있는 실행계획을 판별하여 실행한다.
SHOW INDEX FROM {테이블 명}
명령을 통해 만들어진 인덱스를 확인할수있다.
| table | Non_unique | Key_name | Column_name |
| tb_member | 0 | PRIMARY | id |
| tb_member | 0 | UK_e16ra6s3dnftoqj6d9u7rn2a5 | nick_name |
위처럼 id 가 primary , nick_name 가 unique 로 인해 만들어진 index 를 확인할수있다.
또한 Explain 명령을 통해 옵티마이저가 쿼리 실행을 결정하는 방법을 확인할수있다.
EXPLAIN SELECT * from tb_member WHERE id = 500;
EXPLAIN SELECT * from tb_member WHERE nick_name = '단정한_어묵_46';
| id | select_type | table | type | possible_keys | key | key_len | ref | rows |
| 1 | SIMPLE | tb_member | const | PRIMARY | PRIMARY | 8 | const | 1 |
| 1 | SIMPLE | tb_member | const | UK_e16ra6s3dnftoqj6d9u7rn2a5 | UK_e16ra6s3dnftoqj6d9u7rn2a5 | 1022 | const | 1 |
그렇다면 index 가 없는 컬럼은 어떤 실행 계획을 가지고있을까
EXPLAIN SELECT * from tb_member WHERE email = '9557m462eh@random.com';
| id | select_type | table | type | possible_keys | key | key_len | ref | rows |
| 1 | SIMPLE | tb_member | ALL | 13829 |
Type 와 rows 를 확인해보니 모든 컬럼을 조회하는것을 볼수있다.
이렇게 써볼수있지만 사실 이게 인덱스를 잘 쓰고 있다고 할수는없다.
unique 제약조건으로 인한 자동 생성된 인덱스와
unique 인덱스를 직접 생성했을때의 기능의 차이가있다.
만드는것 부터 차이가있는데
unique 제약 조건은 결국 컬럼이 중복값을 가지면 안되지만
unique 인덱스는 인덱스 대상이 중복값을 가지더라도 여러 컬럼을 조합해서 중복값을 없앨수있다면 이를 unique index 로 지정할수있다.
기능적인 차이로는
unique 제약 조건에서는 insert, update 쿼리가 끝날때 중복여부를 확인하고
unique index 에서는 쿼리의 건 마다 중복값을 확인하는 차이가있다.
이럴경우 문제는
unique index 로 잡힌 테이블의 다수의 row 를 update 하다가 중복이 발생하는경우 즉시 알수있지만
unique 제약 조건 에서는 모든 동작이 끝난후에 확인할수있기에 오랜 시간이 걸린다.
검색 알고리즘
데이터 베이스는 페이지 라고 하는 저장 공간 단위로 데이터를 저장한다.
Full Table Scan
인덱스를 사용하지않다면 기본적인 알고리즘이며
찾는 인덱스가없다면 결국 이 알고리즘이 사용된다.
이름 그대로 처음부터 끝까지 데이터를 모두 읽어서 비교하는 형태이다.
이러한 방식은 적용가능한 인덱스가 없거나, 크기가 작은 데이블일 경우 이 방식을 사용한다.
B-Tree
B-Tree = Balanced-Tree
index에서 흔하게 사용되는 알고리즘이다.
정렬된 데이터를 절반으로 잘라서 가운데부터 원하는 값 보다 작냐 크냐로 왼쪽 오른쪽을 가는 이진탐색,
이진트리는 균형이 잡힌 트리일경우 O(Log n) 의 속도를 낼수있지만
만약 한쪽으로 치우쳐진 균형없는 트리일경우 최악의 경우 O(n) 속도가 나는 문제가있다.
이러한 단점을 보안한 알고리즘이다.
모든 데이터는 정렬을 이루고 페이지 별로 구별되어있으며
Root Page , Branch Page , Data Page 라 부르는 노드 들로 구성되어있다.
Data Page 는 Reaf 페이지 라고도 부르며 실제 데이터가 존재하는 페이지이다.
각 노드는 자신의 key과 다름 노드의 주소 혹은 데이터를 가지고있다.
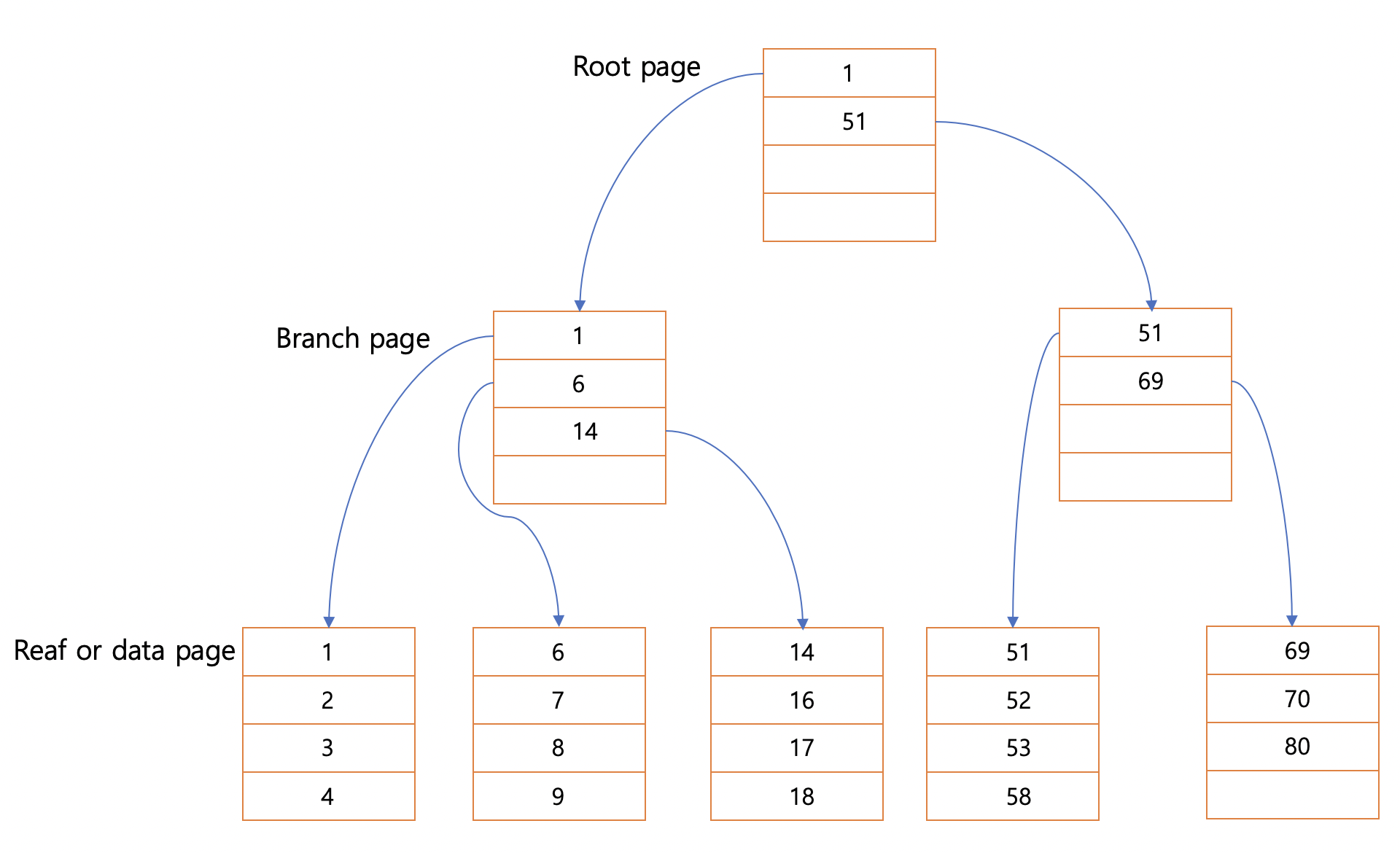
Root 는 Branch 의 해더를 가지고있고 Branch 는 data의 해더를 가지는 구조이다.
이렇게 될경우 14을 조회 하려고하면
root 부터 시작하여 1의 브랜치 페이지를 보고
14의 리프페이지를 보면 데이터를찾을수있게된다.
만약 이것이 풀 스켄이였다면 14번의 비교를 여기서는 3번으로 끝났다
인덱스 의 단점
위에서 언급한것처럼 R 을 위해 CUD 의 성능을 희생하였기에 이부분이 단점이다.
insert 의 경우 중간에 데이터를 삽입하는 작업을 수행하는데
만약 데이터가 삽입되는 페이지가 공간이 존재한다면 그대로 들어가거나 근처 데이터를 이동시켜
들어가기에 큰 부담은 없지만(부담이 아에없는게 아님)
해당 페이지가 가득차서 다른페이지를 추가하는 작업을 진행해야여하는경우
매우 부담스러운 작업이 된다.
이 작업을 페이지 분활 이라한다.
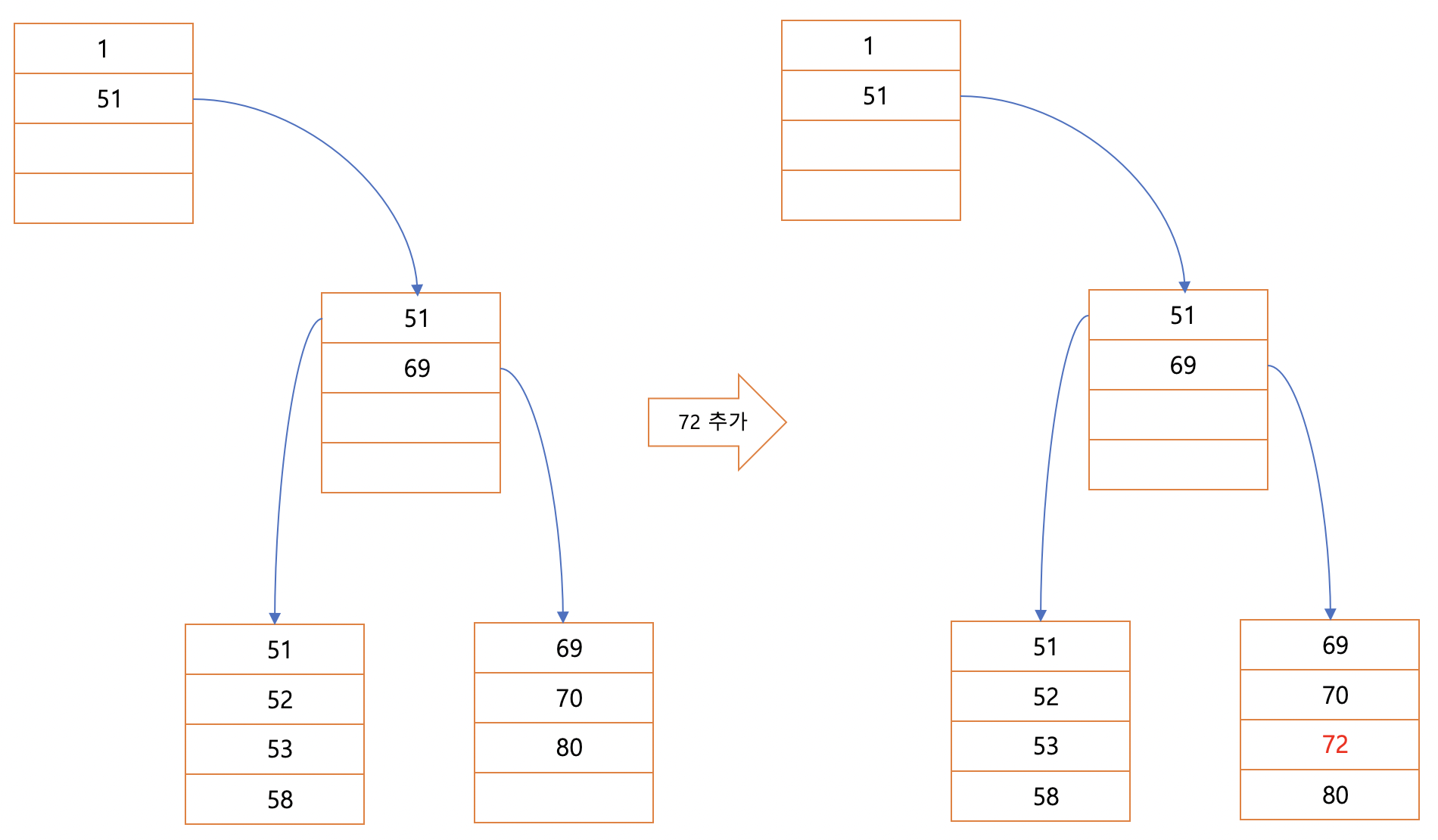
위와같은 상태에서 72의 데이터를 넣게된다면
페이지 4번의 80이 한칸 뒤로가고 중간에 72가 들어가게된다
이렇게 하나의 페이지의 변경은 부담스럽지 않은 작업이나
만약
여기서 이번엔 73를 넣어야한다면
페이지 4번에 넣어야겠지만 데이터가 가득차서 넣을수없다
이땐 비어있는 페이지를 확보한후 문제가 있는 페이지의 데이터를 공평하게 나누어 저장한다.
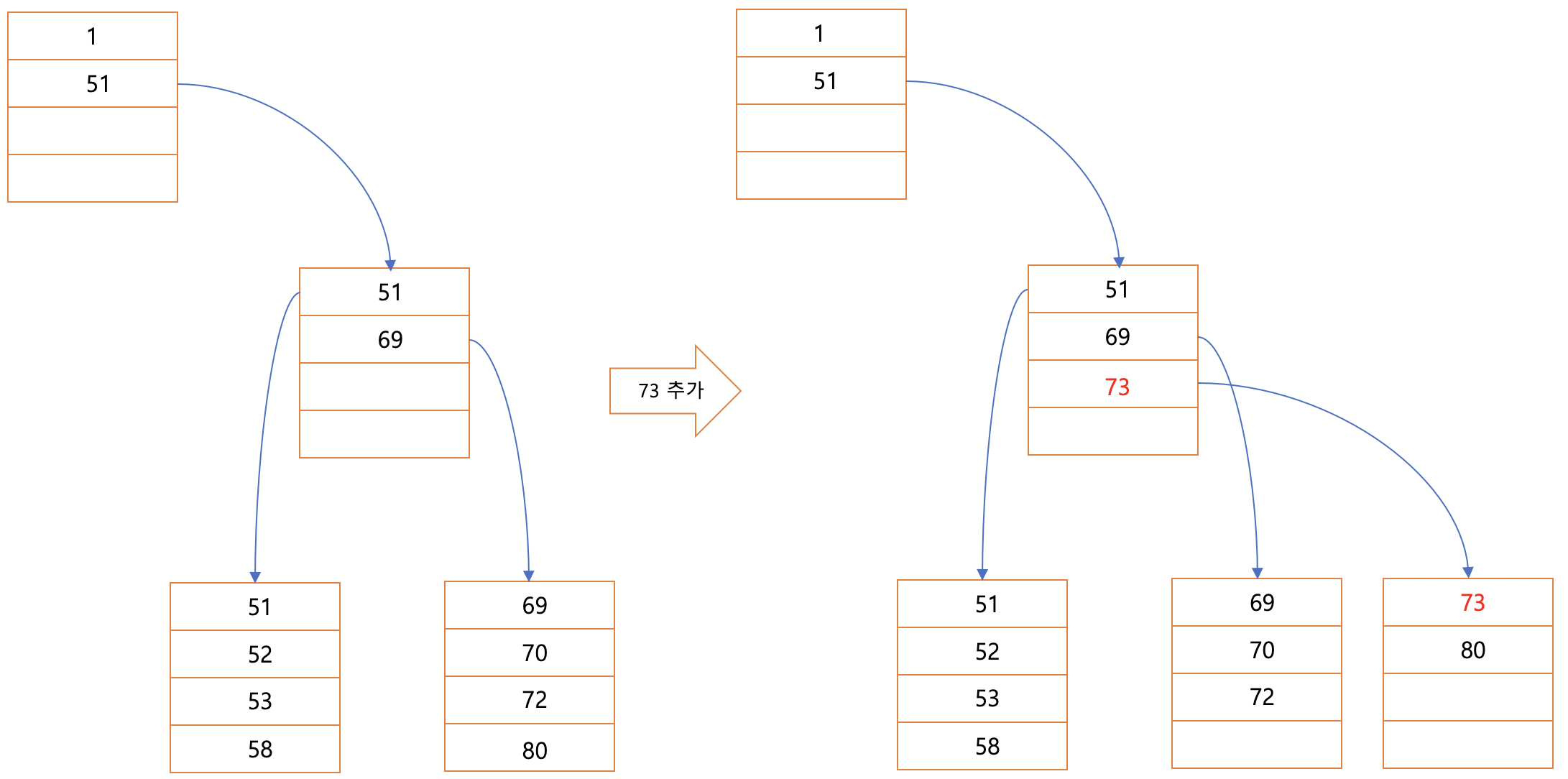
이는 데이터베이스에 부담스러운 작업이며
페이지가 추가되었기에 당연히 상위 페이지의 추가가 발생한다.
만약 10000명의 회원 랭킹에서 신규 회원을 1등으로 하고싶다면
10000명의 회원이 이동을 해야한다.
Clustered Index , Non-Clustered
데이터 베이스 인덱스는 두가지로 구분된다.
Clustered 라는 용어는 군집화의 의미를 가지고있는데
Clustered index 라는 말은 곧 군집화된 인덱스 라는 의미를 가지게된다.
쉽게 보면 Clustered Index 는 위에서 본것같은 index를 할때
데이터가 들어올때마다 물리적으로 정렬하여 index구조를 잡는 방식이며 테이블당 하나의 인덱스만 존재한다.
Non-Clustered는 데이터가 들어올때 데이터를 정렬하지않고 별도의 공간을 만들어
데이터를 추가할때 Clustered 의 단점을 보안했으나
약 10%의 별도의 공간을 사용해야한다.
Clustered Index
💡 PK 제약 조건을 통해 자동 생성되는 방식이다.
💡 테이블당 1개만 존재한다.
군집화된 인덱스는
어떠한 가리키는 무언가를 가지고있는 데이터의 집합 이라 할수있는데
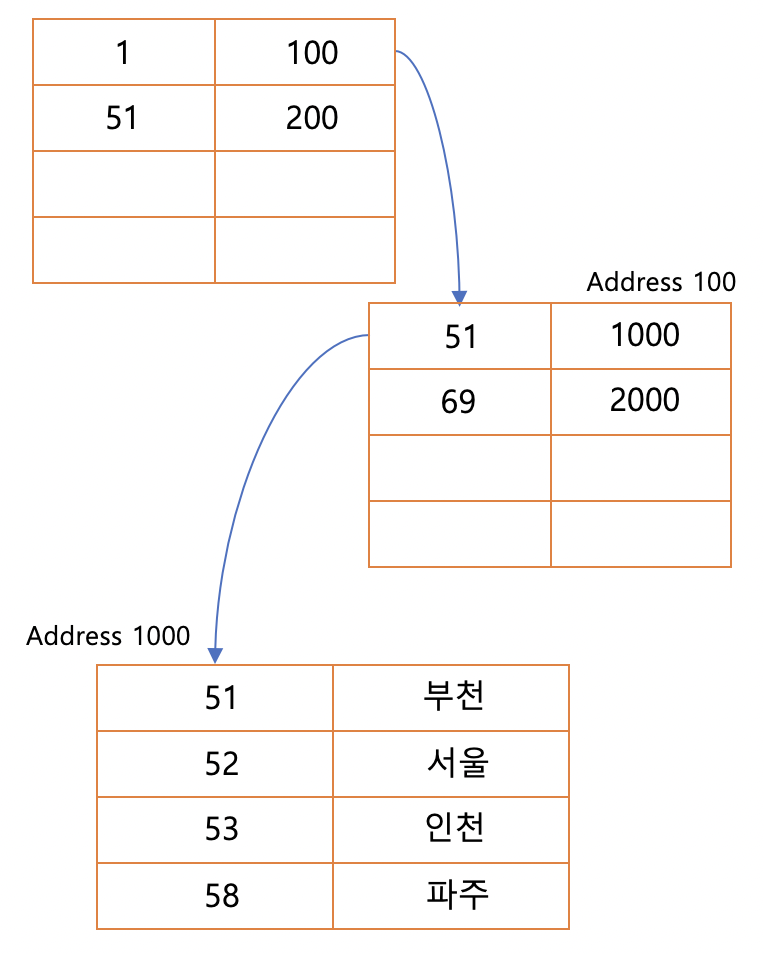
위와같은 형태의 데이터를 가리킬수있는 인덱스 값을 가지고있는 형태이다.
데이터를 정렬하여 검색 속도를 향상시켰지만 새로운 데이터를 삽입할때 많은 단점이 소모되는 방식이다.
Non-Clustered
💡 Unique 제약 조건을 통해 자동 생성되는 방식이다. (물론 직접 생성도 가능)
💡 정렬이 되지않았다는건 인덱스가 정렬되지않은것이 아닌 데이터가 정렬되지 않았음을 말한다.
💡 비군집 인덱스는 결국 군집 인덱스의 PK 를 가리키고있다.
군집화의 반대인 비군집 인덱스는
정렬하지않은 방식이다.
마치 책의 목차와 같은 역활을하며
각 데이터 행이 독립 적이며 이 독립적인 데이터는 인덱스키와 데이터를 가리키는 포인터를 가지고있다.
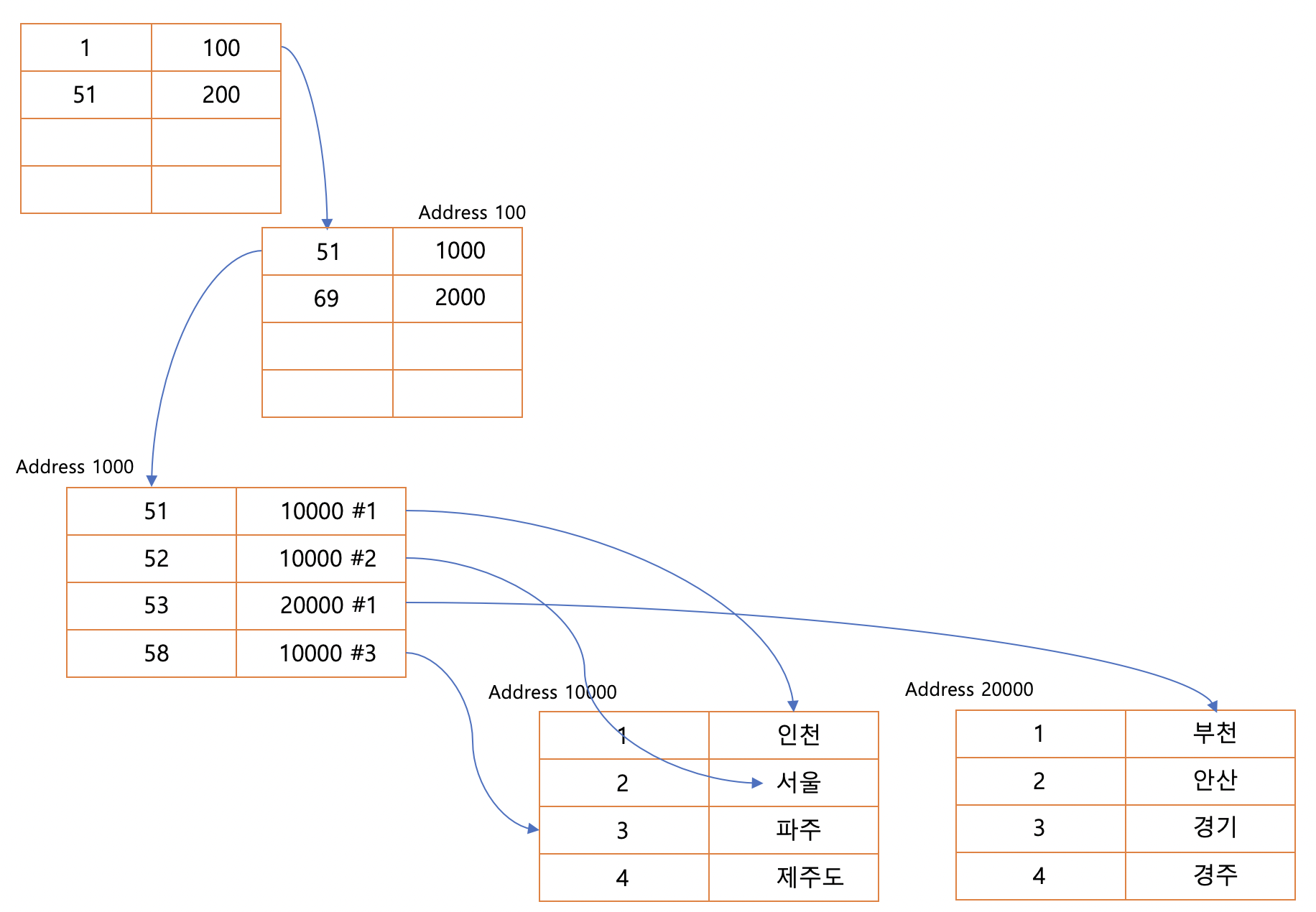
즉 데이터가 추가 될때 index 는 정렬이 되지만
데이터 페이지가 정렬될 필요가없다.
그렇지만 리프페이지가 데이터를 가지고있지 않고 데이터 페이지의 주소를 가지고 있기 때문에
Clustered Index 보다 노드 이동이 증가하기에 비교적 느리다고 할수있지만
데이터 정렬이 필요없다는 장점이 있다.
또 다른 단점으로는
위의 그림과 같은 상황에서
범위 검색을 하려고 할때
예로 51부터 53 을 조회 하려고할때 Clustered Index 에서는 리프 페이지 하나만 탐색 하면되지만
Non-Clustered Index 에서는 리프페이지와 10000, 20000 의 데이터 페이지를 조회해야한다.
어떤 컬럼에 index 를 설정할까
컬럼에 index 적용 여부를 정하는 핵심적인 기준이 존재한다.
카디널리티가 높은 컬럼
카디널리티는 특정 데이터 집앞의 유니크한 값의 개수를 말한다.
성별 이라는 컬럼의 경우 ‘남자’, ‘여자’ 라는 값을 가진다면 카디털리티의 값인 2이며
높은 카디널리티를 선택하는 이유는 데이터들이 다양한 값을 가지고있다는것이다.
선택도가 낮은 컬럼
하나의 컬럼이 가지고있는 값으로 검색시 여러 row가 찾아지지 않는것이 좋다.
이는 공식이 존재하는데
특정 컬럼값으로 검색되는 row수 / 테이블의 총 row수 *100
위의 계산에서 5~10%를 좋은 컬럼이라 본다.
선택도가 1이되면 row에게 이 컬럼은 유니크 하다는것.
조회 활용도가 높은 컬럼
해당 컬럼이 where로 인해 많이 조회되는지 판단하면 된다.
수정 빈도가 낮은 컬럼
인덱스의 단점으로 인해 수정 빈도가낮을수록 좋다.
즉 하나의 컬럼에 들어갈수있는 데이터 종류가 다양하며
조회를 자주하고 수정이 잘 발생하지 않는 컬럼이 index로 지정하기좋다.
대표적으로 member 테이블에서는 name 일것.
정리
- 우린 모두 index를 알게모르게 사용하고있었다
- PK 가 있다면 자동으로 Clustered Index 를 생성해준다
- unique 제약 조건이 있다면 자동으로 Non-Clustered Index 를 생성해준다.
- Clustered Index 는 검색 속도가 빠르나 데이터 추가시 페이지 분활로 인한 부담이 있다.
- Non-Clustered Index 는 검색 속도가 Clustered Index 에 비해 느리지만 데이터 추가의 부담이 적다
- Clustered Index 의 부담을 생각하면 우리가 왜 PK를 Auto_Increment 옵션을 주는지 이해할수있을것
'ETC' 카테고리의 다른 글
| Value Object 가 최고다. (1) | 2023.06.14 |
|---|---|
| GitHub Actions 사용하여 CI/CD 적용해보기 (0) | 2023.02.18 |
| 그놈의 REST 한 API (0) | 2022.09.27 |
| HashMap 내용물 이해하기 (0) | 2022.09.10 |
| RVA to RAW 쉽게 계산하기 (0) | 2022.09.04 |


